Can anyone recommend a Tflite Colab Notebook for VOXL2 Training
-
@thomas @sansoy Has anyone tried integrating a yolov8n model, I have a tflite fp16 quantized model but this line in the modal ai documentation says that any other model architecture apart from the ones mentioned here cannot be used,
 file:///home/swarm_researchers/Pictures/Screenshots/Screenshot%20from%202024-01-27%2021-34-41.png
file:///home/swarm_researchers/Pictures/Screenshots/Screenshot%20from%202024-01-27%2021-34-41.png -
@sansoy has been able to get custom models working, but you'll have to follow the steps we took in the posts above. Let me know how I can best help!
Thomas
-
@thomas Also the model which @sansoy used was yolov5n, and I checked most of the code of inference helper it was related to yolov5, is the tflite server compatible to any yolo model?
Actually in a separate post I asked about object tracking with yolo models, from the article I read here and referring to the individual tracker documentations, somehow I need to have access to the tflite model to run these trackers, is there a way to integrate the trackers into the voxl-tflite-server, as the documentation says it provides hardware acceleration.
https://www.datature.io/blog/implementing-object-tracking-for-computer-vision
-
@thomas Edit about upgrading the sdk to nightly build: I tried it on my starling v2 drone, but somehow the nighly build is unable to write px4 parameters and the upgrade ends up failing (firmware issue link I reverted the sdk back to sdk 1.0 and the drone fortunately works again, but how would I avoid the number of classes bug which you highlighted above. I also have modified yolo to detect just one class.
-
The goal of
voxl-tflite-serveris to provide an example of how ML models can be used in the VOXL ecosystem, not as an in-depth, well-tested framework. Your custom YOLO model might work, it might not. At lot of the logic in the server for math regarding the raw tensor data that the model produces has been written specifically for the models we put onboard. A good example of this is how the module postprocesses our YoloV5 network here; if your output tensor is the same format then you'll probably get good results out. If not, then you won't.So I would follow the steps we took above to get a custom YOLO model working. If it doesn't work, you'll need to write your own C++ module that subscribes to an input camera pipe using
libmodal-pipe, creates aTFLite::Interpreterthat works with your model, and then parses the output tensor from your YOLO model. I'm happy to help you out with whatever you need here.No idea what's going on with the PX4 params, that's outside of my domain. However if you're having problems with TFLite server regardless, it might just be best to code up your own approach as outlined above.
Keep me in the loop, happy to help you out however you need!
Thomas Patton
-
@thomas I used my custom dataset to retrain yolo v5 model and I get similar performance on my desktop. About the sdk is it possible to get the changes you did to the tflite server in a build closer to sdk 1.1.2 for the starling v2. I was able to upgrade and fly the drone till that version of the sdk 1.1.2 that means that whatever nightly releases happened after that might have same px4 related bugs.
About the Multi object tracking, if I have to rewrite the same thing which deepsort or any other algorithm did that would entirely have to be in C++? Also if I want to run any ML/AI model without the tflite server, lets say in a python script (running on docker container onboard voxl2) it would not get any of the gpu hardware acceleration? I ask this questions because writing a sdk level software is much difficult. Instead if we had drivers like in our desktop pcs (CUDA like drivers) which when invoked in a python script could readily make the acceleration available. It would make ML deployment much easier.
-
M Moderator referenced this topic on
-
Check your other post for details on getting the nightly builds.
VOXL can run any language you install on it, Python or C++ or whatever else. However if you want to read camera data in in real-time, our supported solution is through
libmodal-pipewhich is written in C++. As for the hardware acceleration, it may be possible to use it in Python but we only have it documented for C++ via thennapi_delegateclass inTFLitewhich you can see here. There might be other methods for acceleration but this is all we've used and tested so far.That is to say that we don't currently have hardware accelerators built into a general purpose library like CUDA. I would love to write a library like that but we simply don't have the business demand for it right now.
Hope this helps,
Thomas Patton
-
@thomas what is the purpose of the quantization script mentioned in the voxl docs, Is it the same as model conversion given in yolov5 documentation
https://docs.modalai.com/voxl-tflite-server/#using-your-own-modelsCan I use the model conversion script given over here?
-
I think that the yolov5 one will work as I'm pretty sure that's what I used to make a custom one at some point. I think the most important part is that the quantization is FP16 so make sure you add that
--halfarg. Definitely try it out and let me know how it goes.Thomas
-
@thomas Actually I did it without the --half argument and it works onboard the voxl, here's the result
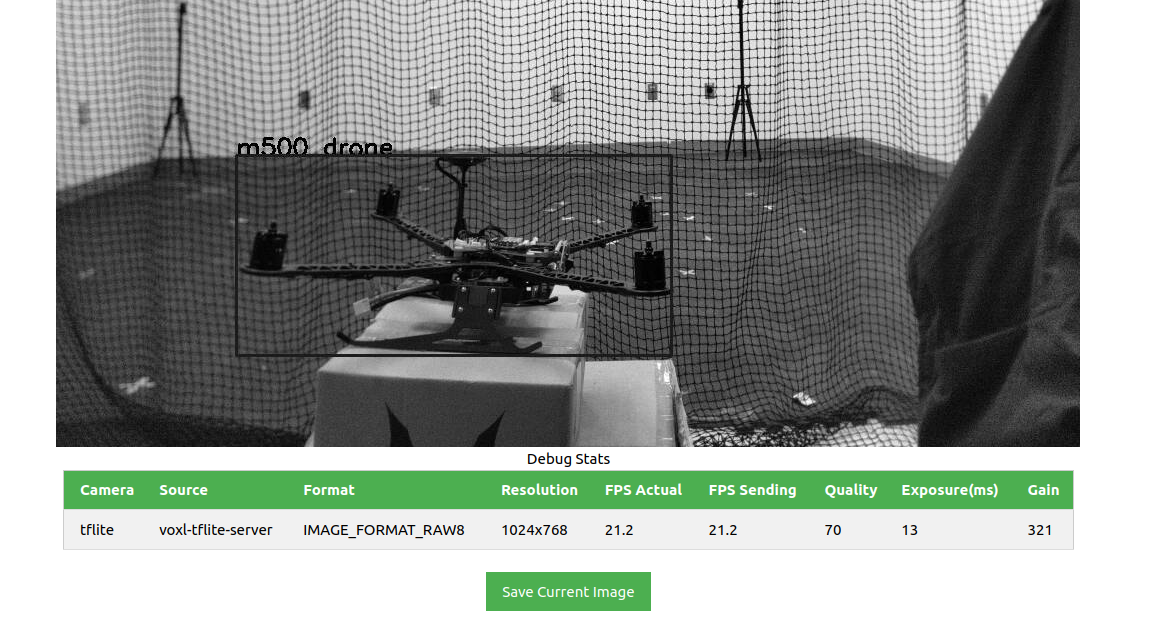
Also I don't know why but when I checked in netron the input image size was give 3,640,640 while voxl shows that the image resolution is 1024x768. I also read somewhere in the tflite documentation that the image size if changed needs to be updated in inference helper. I didn't do that too
-
Yeah, for reference almost all of the
voxl-tflite-servercode and documentation was written by a former employee so I don't always have the source of ground truth for things. I think there may be some logic in there that deals with reshaping the output tensors but I'm not fully sure. Same thing with the--halfargument, I think we advise it but if you can get your model to work without quantization that's awesome. Glad to see it's working!! The results look good")
Keep me posted on how I can help,
Thomas Patton
-
-
A Ajay Bidyarthy referenced this topic on