Custom YOLO model on VOXL1
-
I fine-tuned a YOLOv8 model and converted it to tflite according to the script and specifications in the ModalAI documentation (quantizing, 16-bit, etc), and made sure I used tensorflow 2.2.3 which converting it (since it says VOXL1 has to have that version for the model). I then scp'd it over to my VOXL along with the labels file and changed the names to replace the old yolo model (don't worry, I renamed the old stuff to old_<name> so its still on there.) Now the tflite server won't pop up in the voxl-portal and the program ends up stuck and not responding when I execute the tflite server even in debug mode. Below is the Netron analysis of the model aboard originally was:
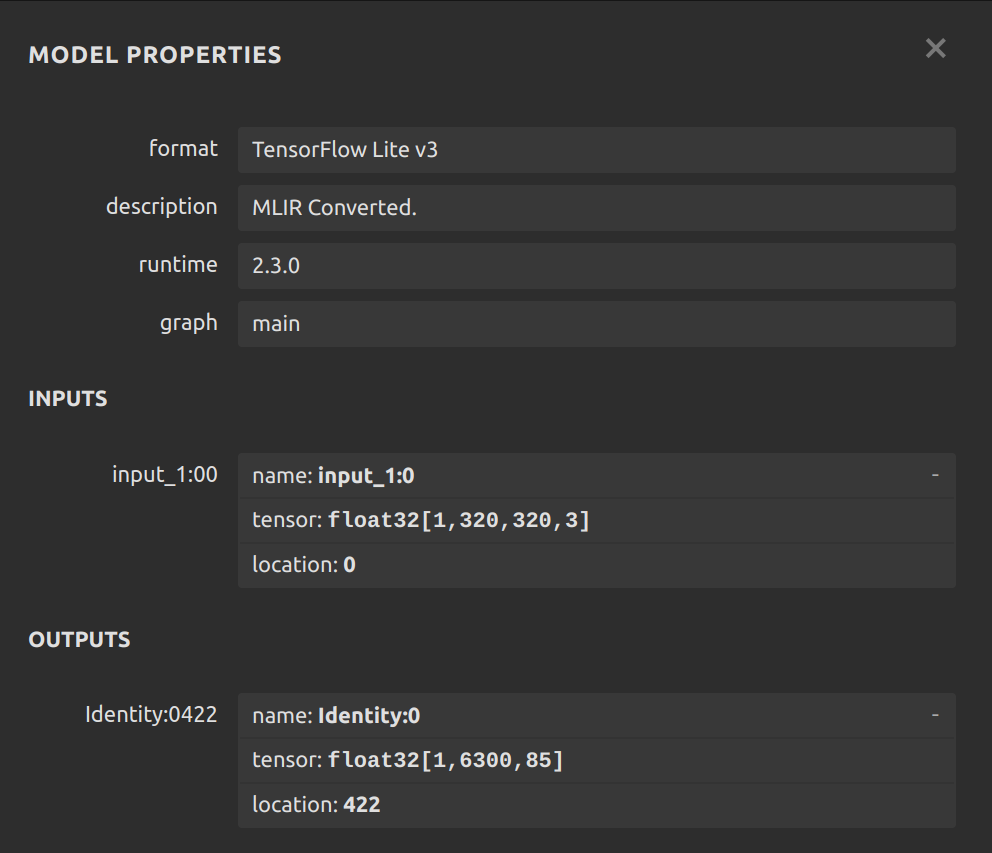
The analysis of mine is:
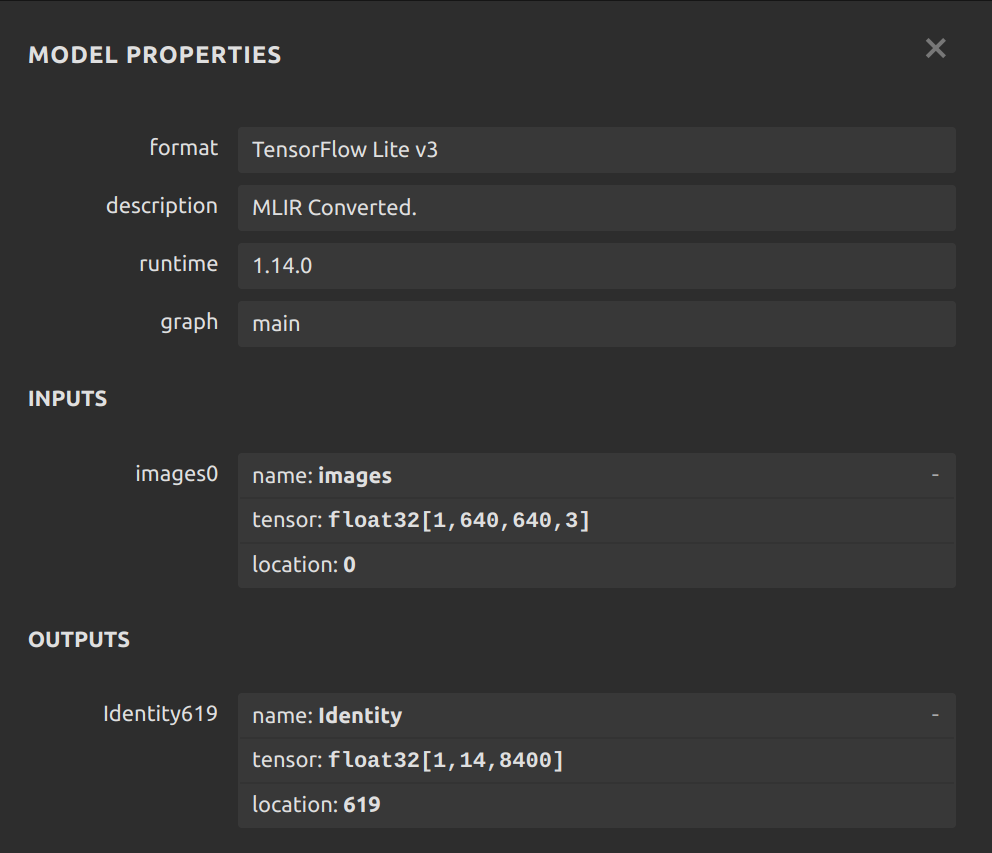
I see that the I/O sizes are different. It also appears that the axes are flipped in the output layer. My questions are: 1) can I use YOLOv8 or should I use v5 and 2) should I be exporting the model with 320,320 instead of 640,640, or are variable sizes okay?
I also saw a result on another forum post that was solved that said there was a seg fault anytime there are not 80 classes exactly on a YOLO model, which could be the issue, but I wanted to make sure these other items weren't of concern either.
-
I also tried using a YOLOv5 model with the same conversion process and kept all 80 classes to rule out that being the error. To my surprise it appeared in the voxl-portal but only after a long delay and with 2 FPS and super long inference times. Would this be a product of the model being too big?
-
I have now installed voxl-tflite-server_0.3.2_202401161223.ipk to upgrade the tflite server to the night that the 80 class restriction was fixed (I assuming this is the correct one to install since on the forum it said on Jan 16 that it would be fixed in the nightly SDK release.) When I ran the YOLOv8 model trained on 10 classes (making sure the labels file was correct as well) before doing this, it just never started up or showed anything when running tflite-server, but now when running that same model, I get these results:
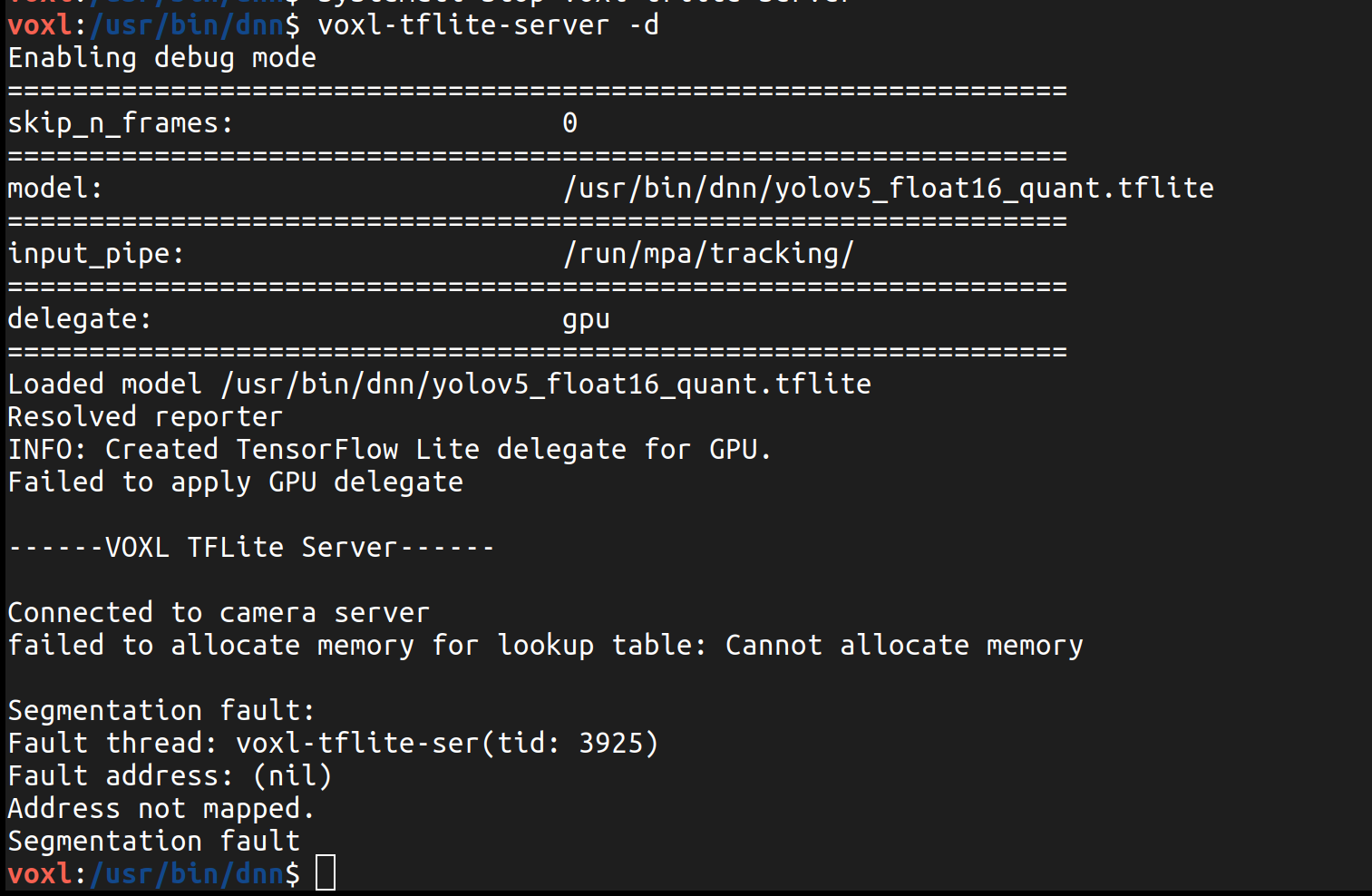
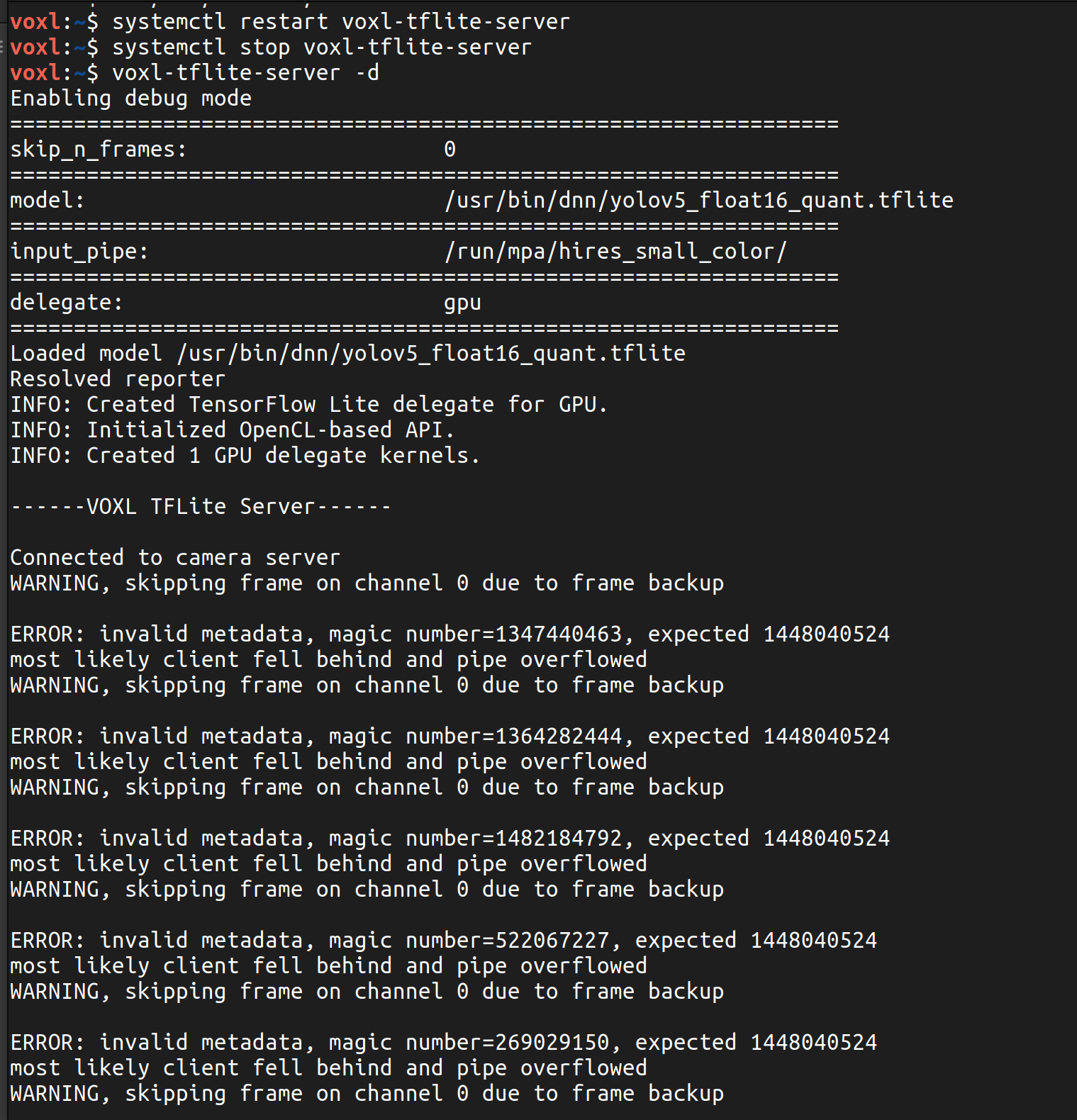
-
I have now installed voxl-tflite-server_0.3.2_202401161223.ipk to upgrade the tflite server to the night that the 80 class restriction was fixed (I assuming this is the correct one to install since on the forum it said on Jan 16 that it would be fixed in the nightly SDK release.) When I ran the YOLOv8 model trained on 10 classes (making sure the labels file was correct as well) before doing this, it just never started up or showed anything when running tflite-server, but now when running that same model, I get these results:
Hey, happy to try and help you with this as I'm the maintainer of
voxl-tflite-server. In general we seldom test things on VOXL 1 so I'm not super educated on the problem you might be facing. You mentioned poor performance with low framerates and long inference times, this could definitely be the product of using the older chipset.Do you mind testing some of the models that are already onboard? I would be curious to know how they compare to these numbers.
Thanks!
Thomas Patton -
Hey, happy to try and help you with this as I'm the maintainer of
voxl-tflite-server. In general we seldom test things on VOXL 1 so I'm not super educated on the problem you might be facing. You mentioned poor performance with low framerates and long inference times, this could definitely be the product of using the older chipset.Do you mind testing some of the models that are already onboard? I would be curious to know how they compare to these numbers.
Thanks!
Thomas Patton@thomas hey there Thomas, thank you for your reply!
Understandable that it's harder because of VOXL 1 rather than 2. I've tested all the other models on board and they produce very similar results as described by the Deep Learning documentation guide. The YOLOv5 model already on board gives about 20 FPS and 40-50ms inferences with the hires small color camera (similar with other pre-loaded models both on hires and tracking cameras). So, it seems like the VOXL 1 is running YOLO at a good speed, just not the one I uploaded. However, it seems the one I uploaded is much bigger (180MB) as compared to the one that came on it (14MB). I used the float 16 quantization as described in the documentation, but should I try using a smaller model like YOLOv5s versus YOLOv5x?
-
@thomas hey there Thomas, thank you for your reply!
Understandable that it's harder because of VOXL 1 rather than 2. I've tested all the other models on board and they produce very similar results as described by the Deep Learning documentation guide. The YOLOv5 model already on board gives about 20 FPS and 40-50ms inferences with the hires small color camera (similar with other pre-loaded models both on hires and tracking cameras). So, it seems like the VOXL 1 is running YOLO at a good speed, just not the one I uploaded. However, it seems the one I uploaded is much bigger (180MB) as compared to the one that came on it (14MB). I used the float 16 quantization as described in the documentation, but should I try using a smaller model like YOLOv5s versus YOLOv5x?
Yeah, I'd be curious to know what your results are like using a custom YOLOv5 model. If things are still slow, the issue might be in your quantization process. However if it speeds up, it may just be that the model architecture is too big.
I have it on my to-do list at some point in the next few weeks to add YOLOv8 to our list of default models so when/if I do that I'll keep you posted with the results of that as well.
Keep me posted on how I can be of assistance!
Thomas Patton
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login