Voxl2 custom segmentation model lead to unwanted reboot
-
Hello everyone, I'm currently dealing with an issue while running a custom segmentation model on the tflite server. The board is maintaining an approximate inference time of 5Hz, which is good. However, I'm facing problems when trying to pass segmentation masks over pipes to be retrieved by the voxl-mpa-to-ros pipeline.
I've implemented a solution using a new data structure for the masks, which are larger than normal bounding boxes. I publish these masks to the pipe, and on the receiving end, the mpa_to_ros node reads and forwards the mask as a custom message. This process worked well with SDK 0.9.5, but after upgrading to SDK 1.1.2, the board crashes and reboots when attempting to subscribe to the tflite data (I can get few samples but then it crash). The code remains the same, and I've also tested changing the buffer, but the issue persists.
Interestingly, subscribing to the camera portal works fine, but subscribing to the pipe causes the crash. I'm wondering if it could be a problem with the SDK, perhaps an issue with memory management causing the board to crash and reboot. Or could it be a power supply problem?
Has anyone else experienced a similar issue after upgrading to SDK 1.1.2, or does anyone have insights into what might be causing the problem? Any suggestions for troubleshooting or potential solutions would be greatly appreciated. Thank you!
-
Hello everyone, I'm currently dealing with an issue while running a custom segmentation model on the tflite server. The board is maintaining an approximate inference time of 5Hz, which is good. However, I'm facing problems when trying to pass segmentation masks over pipes to be retrieved by the voxl-mpa-to-ros pipeline.
I've implemented a solution using a new data structure for the masks, which are larger than normal bounding boxes. I publish these masks to the pipe, and on the receiving end, the mpa_to_ros node reads and forwards the mask as a custom message. This process worked well with SDK 0.9.5, but after upgrading to SDK 1.1.2, the board crashes and reboots when attempting to subscribe to the tflite data (I can get few samples but then it crash). The code remains the same, and I've also tested changing the buffer, but the issue persists.
Interestingly, subscribing to the camera portal works fine, but subscribing to the pipe causes the crash. I'm wondering if it could be a problem with the SDK, perhaps an issue with memory management causing the board to crash and reboot. Or could it be a power supply problem?
Has anyone else experienced a similar issue after upgrading to SDK 1.1.2, or does anyone have insights into what might be causing the problem? Any suggestions for troubleshooting or potential solutions would be greatly appreciated. Thank you!
Hey Riccardo, happy to try and help you out with this.
Per the repository graph for tflite-server it doesn't seem like we've changed anything in terms of what's being released in the SDKs. Of course, as you point out, the issue could be related to something entirely different.
When you're passing the segmentation masks over
libmodal-pipe, can I ask how you're doing it? If you're trying to put that data into anai_detection_tit likely isn't well-supported and you may be using to much memory (as you point out). If this were the case, you'd be better of making your own struct for the masks and then setting up your own pipe that can appropriately handle the data.Let me know, hopefully we can get to the bottom of this!
Thomas Patton
-
Hey Riccardo, happy to try and help you out with this.
Per the repository graph for tflite-server it doesn't seem like we've changed anything in terms of what's being released in the SDKs. Of course, as you point out, the issue could be related to something entirely different.
When you're passing the segmentation masks over
libmodal-pipe, can I ask how you're doing it? If you're trying to put that data into anai_detection_tit likely isn't well-supported and you may be using to much memory (as you point out). If this were the case, you'd be better of making your own struct for the masks and then setting up your own pipe that can appropriately handle the data.Let me know, hopefully we can get to the bottom of this!
Thomas Patton
Hi @thomas,
I createad a custom
ai_segmentation_tstruct as#define MASK_HEIGHT 480 #define MASK_WIDTH 640 typedef struct ai_segmentation_t { uint32_t magic_number; int64_t timestamp_ns; uint32_t class_id; int32_t frame_id; char class_name[BUF_LEN]; char cam[BUF_LEN]; bool first_segmentation; bool last_segmentation; float class_confidence; float detection_confidence; float x_min; float y_min; float x_max; float y_max; int8_t mask[MASK_HEIGHT * MASK_WIDTH]; // 2D array for segmentation mask } __attribute__((packed)) ai_segmentation_t;which are then written down to the pipe as (main.cpp file of the voxl-tflite-server)
std::vector<ai_segmentation_t> detections; if (!inf_helper->postprocess_seg(output_image, detections, last_inference_time)) continue; if (!detections.empty()) { for (unsigned int i = 0; i < detections.size(); i++) { pipe_server_write(DETECTION_CH, (char *)&detections[i], sizeof(ai_segmentation_t)); } } new_frame->metadata.timestamp_ns = rc_nanos_monotonic_time(); pipe_server_write_camera_frame(IMAGE_CH, new_frame->metadata, (char *)output_image.data); }And retrieved by the ai_detection_interface.h in the callback function of voxl-mpa-to-ros
static void _helper_cb(__attribute__((unused)) int ch, char *data, int bytes, void *context) { AiDetectionInterface *interface = (AiDetectionInterface *)context; if (interface->GetState() != ST_RUNNING) return; ros::Publisher &publisher = interface->GetPublisher(); voxl_mpa_to_ros::AiSegmentation &obj = interface->GetSegMsg(); std::vector<voxl_mpa_to_ros::AiSegmentation> obj_array; voxl_mpa_to_ros::AiSegmentationArray obj_arrayMsg; int n_packets = bytes / sizeof(ai_segmentation_t); ai_segmentation_t *detections = (ai_segmentation_t *)data; bool first_segmentation = false; bool last_segmentation = false; for (int i = 0; i < n_packets; i++) { if (detections[i].magic_number != AI_DETECTION_MAGIC_NUMBER) return; // publish the sample obj.timestamp_ns = detections[i].timestamp_ns; obj.class_id = detections[i].class_id; obj.frame_id = detections[i].frame_id; obj.class_name = detections[i].class_name; obj.cam = detections[i].cam; obj.class_confidence = detections[i].class_confidence; obj.detection_confidence = detections[i].detection_confidence; obj.x_min = detections[i].x_min; obj.y_min = detections[i].y_min; obj.x_max = detections[i].x_max; obj.y_max = detections[i].y_max; obj.first_segmentation = detections[i].first_segmentation; obj.last_segmentation = detections[i].last_segmentation; if (detections[i].first_segmentation) { first_segmentation = true; } if (detections[i].last_segmentation) { last_segmentation = true; } last_segmentation = true; first_segmentation = true; obj.mask = std::vector<int8_t>(detections[i].mask, detections[i].mask + sizeof(detections[i].mask) / sizeof(detections[i].mask[0])); // add the obj_array.push_back(obj); } obj_arrayMsg.segmentation_array = obj_array; if (n_packets > 0 && publisher.getNumSubscribers() > 0 && first_segmentation && last_segmentation) { publisher.publish(obj_arrayMsg); } return; }and inside the ai_detection_interface has the ai_segmentation and ai_segmentation_array defined as (same as the tflite-server):
typedef struct ai_segmentation_t { uint32_t magic_number; int64_t timestamp_ns; uint32_t class_id; int32_t frame_id; char class_name[BUF_LEN]; char cam[BUF_LEN]; bool first_segmentation; bool last_segmentation; float class_confidence; float detection_confidence; float x_min; float y_min; float x_max; float y_max; int8_t mask[MASK_HEIGHT * MASK_WIDTH]; // 2D array for segmentation mask } __attribute__((packed)) ai_segmentation_t; typedef struct ai_array_segmentation_t { std::vector<ai_segmentation_t> segmentations; } __attribute__((packed)) ai_array_segmentation_t;The problem is that the model runs and the output of the detection makes sense :
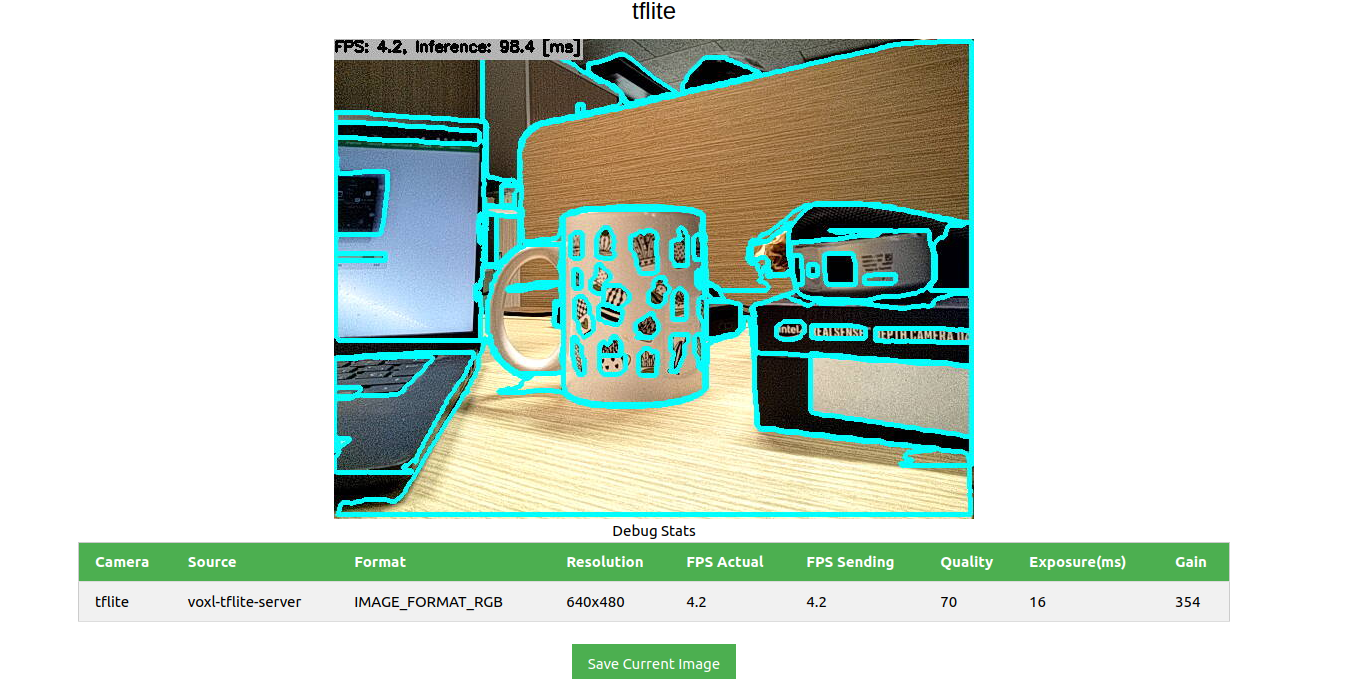
The usage of the GPU is:
[Name Freq (MHz) Temp (C) Util (%) ----------------------------------- cpu0 1075.2 67.1 33.30 cpu1 1075.2 65.5 26.08 cpu2 1075.2 65.9 26.77 cpu3 1075.2 65.9 26.34 cpu4 710.4 67.1 16.08 cpu5 710.4 65.5 25.00 cpu6 710.4 65.5 23.67 cpu7 844.8 67.1 6.61 Total 67.1 22.98 10s avg 22.78 ----------------------------------- GPU 587.0 67.1 97.92 GPU 10s avg 49.08 ----------------------------------- memory temp: 65.0 C memory used: 1125/7671 MB ----------------------------------- Flags CPU freq scaling mode: auto Standby Not Active -----------------------------------]However, when I attempt to retrieve the segmentation from the voxl-mpa-to-ros the voxl2 reboot, even though some messages are received. While I might expect a crash at the code level or a segmentation fault, a total reboot occurs, which can create a few problems, especially when flying.
Also even tought it occurs more sporadically, the voxl2 also reboot by simply running the model and displaying on the portal the segmentations. However the voxl-inspect-cpu does not complain about overheating neither I notice any extra memory usage.
Any help is welcome!
")
-
Hi @thomas,
I createad a custom
ai_segmentation_tstruct as#define MASK_HEIGHT 480 #define MASK_WIDTH 640 typedef struct ai_segmentation_t { uint32_t magic_number; int64_t timestamp_ns; uint32_t class_id; int32_t frame_id; char class_name[BUF_LEN]; char cam[BUF_LEN]; bool first_segmentation; bool last_segmentation; float class_confidence; float detection_confidence; float x_min; float y_min; float x_max; float y_max; int8_t mask[MASK_HEIGHT * MASK_WIDTH]; // 2D array for segmentation mask } __attribute__((packed)) ai_segmentation_t;which are then written down to the pipe as (main.cpp file of the voxl-tflite-server)
std::vector<ai_segmentation_t> detections; if (!inf_helper->postprocess_seg(output_image, detections, last_inference_time)) continue; if (!detections.empty()) { for (unsigned int i = 0; i < detections.size(); i++) { pipe_server_write(DETECTION_CH, (char *)&detections[i], sizeof(ai_segmentation_t)); } } new_frame->metadata.timestamp_ns = rc_nanos_monotonic_time(); pipe_server_write_camera_frame(IMAGE_CH, new_frame->metadata, (char *)output_image.data); }And retrieved by the ai_detection_interface.h in the callback function of voxl-mpa-to-ros
static void _helper_cb(__attribute__((unused)) int ch, char *data, int bytes, void *context) { AiDetectionInterface *interface = (AiDetectionInterface *)context; if (interface->GetState() != ST_RUNNING) return; ros::Publisher &publisher = interface->GetPublisher(); voxl_mpa_to_ros::AiSegmentation &obj = interface->GetSegMsg(); std::vector<voxl_mpa_to_ros::AiSegmentation> obj_array; voxl_mpa_to_ros::AiSegmentationArray obj_arrayMsg; int n_packets = bytes / sizeof(ai_segmentation_t); ai_segmentation_t *detections = (ai_segmentation_t *)data; bool first_segmentation = false; bool last_segmentation = false; for (int i = 0; i < n_packets; i++) { if (detections[i].magic_number != AI_DETECTION_MAGIC_NUMBER) return; // publish the sample obj.timestamp_ns = detections[i].timestamp_ns; obj.class_id = detections[i].class_id; obj.frame_id = detections[i].frame_id; obj.class_name = detections[i].class_name; obj.cam = detections[i].cam; obj.class_confidence = detections[i].class_confidence; obj.detection_confidence = detections[i].detection_confidence; obj.x_min = detections[i].x_min; obj.y_min = detections[i].y_min; obj.x_max = detections[i].x_max; obj.y_max = detections[i].y_max; obj.first_segmentation = detections[i].first_segmentation; obj.last_segmentation = detections[i].last_segmentation; if (detections[i].first_segmentation) { first_segmentation = true; } if (detections[i].last_segmentation) { last_segmentation = true; } last_segmentation = true; first_segmentation = true; obj.mask = std::vector<int8_t>(detections[i].mask, detections[i].mask + sizeof(detections[i].mask) / sizeof(detections[i].mask[0])); // add the obj_array.push_back(obj); } obj_arrayMsg.segmentation_array = obj_array; if (n_packets > 0 && publisher.getNumSubscribers() > 0 && first_segmentation && last_segmentation) { publisher.publish(obj_arrayMsg); } return; }and inside the ai_detection_interface has the ai_segmentation and ai_segmentation_array defined as (same as the tflite-server):
typedef struct ai_segmentation_t { uint32_t magic_number; int64_t timestamp_ns; uint32_t class_id; int32_t frame_id; char class_name[BUF_LEN]; char cam[BUF_LEN]; bool first_segmentation; bool last_segmentation; float class_confidence; float detection_confidence; float x_min; float y_min; float x_max; float y_max; int8_t mask[MASK_HEIGHT * MASK_WIDTH]; // 2D array for segmentation mask } __attribute__((packed)) ai_segmentation_t; typedef struct ai_array_segmentation_t { std::vector<ai_segmentation_t> segmentations; } __attribute__((packed)) ai_array_segmentation_t;The problem is that the model runs and the output of the detection makes sense :
The usage of the GPU is:
[Name Freq (MHz) Temp (C) Util (%) ----------------------------------- cpu0 1075.2 67.1 33.30 cpu1 1075.2 65.5 26.08 cpu2 1075.2 65.9 26.77 cpu3 1075.2 65.9 26.34 cpu4 710.4 67.1 16.08 cpu5 710.4 65.5 25.00 cpu6 710.4 65.5 23.67 cpu7 844.8 67.1 6.61 Total 67.1 22.98 10s avg 22.78 ----------------------------------- GPU 587.0 67.1 97.92 GPU 10s avg 49.08 ----------------------------------- memory temp: 65.0 C memory used: 1125/7671 MB ----------------------------------- Flags CPU freq scaling mode: auto Standby Not Active -----------------------------------]However, when I attempt to retrieve the segmentation from the voxl-mpa-to-ros the voxl2 reboot, even though some messages are received. While I might expect a crash at the code level or a segmentation fault, a total reboot occurs, which can create a few problems, especially when flying.
Also even tought it occurs more sporadically, the voxl2 also reboot by simply running the model and displaying on the portal the segmentations. However the voxl-inspect-cpu does not complain about overheating neither I notice any extra memory usage.
Any help is welcome!
Yeah, this is super strange behavior. One thing I want to check on: we allocate a certain number of bytes for the
tflite_datapipe as you can see here. I have no idea why this allocation is not dynamic with respect to the size ofai_detection_tbut I wonder if you might be pushing out too many bytes and the program is quietly segfaulting somewhere. You should also check out any spot in the code that usesai_detection_t(e.g. here) as things might not be getting published correctly for your struct.Hope this helps!
Thomas Patton
-
Yeah, this is super strange behavior. One thing I want to check on: we allocate a certain number of bytes for the
tflite_datapipe as you can see here. I have no idea why this allocation is not dynamic with respect to the size ofai_detection_tbut I wonder if you might be pushing out too many bytes and the program is quietly segfaulting somewhere. You should also check out any spot in the code that usesai_detection_t(e.g. here) as things might not be getting published correctly for your struct.Hope this helps!
Thomas Patton
@Riccardo-Franceschini , can you please tell us how you are powering VOXL2? Specifically, what power regulator are you using to provide 5V and how that regulator is powered?
Also, how quickly after you start your segmentation model does the board reboot? Maybe the GPU does draw a lot of power, but does not have time to heat up sufficiently until a reboot happens (hinting to a possible issue with 5V power quality)
-
@Riccardo-Franceschini , can you please tell us how you are powering VOXL2? Specifically, what power regulator are you using to provide 5V and how that regulator is powered?
Also, how quickly after you start your segmentation model does the board reboot? Maybe the GPU does draw a lot of power, but does not have time to heat up sufficiently until a reboot happens (hinting to a possible issue with 5V power quality)
Hi @Alex-Kushleyev @thomas sorry for the late reply, but the problem seems to be solved when we changed the power module which probably was causing the failure.
-
Hi @Alex-Kushleyev @thomas sorry for the late reply, but the problem seems to be solved when we changed the power module which probably was causing the failure.
All good, glad you got it fixed!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login