voxl 2 Failed to appy GPU delegate
-
Hi @modaltb, @Chad-Sweet
We are facing issue with our own tflite model deployed on voxl2 for text detection bounding boxes.
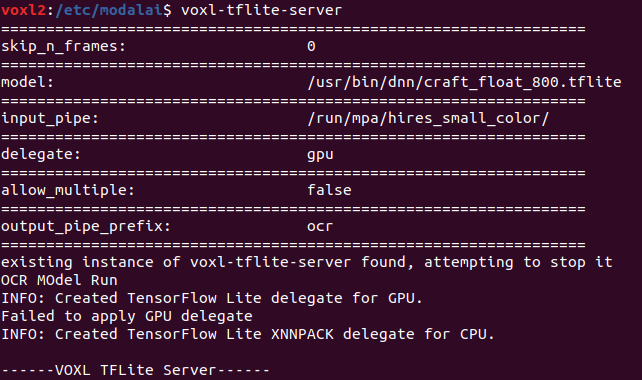
Here we are seeing "Failed to apply GPU deligate".
From our understanding it seems that model will run on CPU in this case. So we are seeing high inference latency of 7-8 seconds, which we want to minimize by running it on GPU.
Can you please help use with this issue.PS: Our tflite model size is 41MB.
Attaching snapshot from voxl2 run for reference.
Thanks
-
Models must contain only instructions from a limited set and be quantized properly to run on the GPU. Please refer to the TensorFlow docs for details:
-
Models must contain only instructions from a limited set and be quantized properly to run on the GPU. Please refer to the TensorFlow docs for details:
This post is deleted! -
Models must contain only instructions from a limited set and be quantized properly to run on the GPU. Please refer to the TensorFlow docs for details:
@James-Strawson Thanks for reply, Will look into it and get back.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login